Fourier Neural Operator
This blog takes about 10 minutes to read. It introduces the Fourier neural operator that solves a family of PDEs from scratch. It the first work that can learn resolution-invariant solution operators on Navier-Stokes equation, achieving state-of-the-art accuracy among all existing deep learning methods and up to 1000x faster than traditional solvers. Also check out the paper, code, article, and project page.
Operator learning
Thinking in continuum gives us an advantage when dealing with PDE. We want to design mesh-indepedent, resolution-invariant operators.
Problems in science and engineering involve solving partial differential equations (PDE) systems. Unfortunately, these PDEs can be very hard. Traditional PDE solver such as finite element methods (FEM) and finite difference methods (FDM) rely on discretizing the space into a very fine mesh. And it can be slow and inefficient.
In the previous post, we introduced the neural operators that use neural networks to learn the solution operators for PDEs. That is, given the initial conditions or the boundary conditions, the neural network directly output the solution, kind of like an image-to-image mapping.
The neural operator is mesh-independent, different from the standard deep learning methods such as CNN. It can be trained on one mesh and evaluated on another. By parameterizing the model in function space, it learns the continuous function instead of discretized vectors.
| Conventional PDE solvers | Neural operators |
|---|---|
| Solve one instance | Learn a family of PDE |
| Require the explicit form | Black-box, data-driven |
| Speed-accuracy trade-off on resolution | Resolution-invariant, mesh-invariant |
| Slow on fine grids; fast on coarse grids | Slow to train; fast to evaluate |
Operator learning can be taken as an image-to-image problem. The Fourier layer can be viewed as a substitute for the convolution layer.
Framework of Neural Operators
Just like neural networks consist of linear transformations and non-linear activation functions, neural operators consist of linear operators and non-linear activation operators.
Let be the input vector, be the output vector. A standard deep neural network can be written in the form:
where are the linear layer or convolution layer, and are the activation function such as ReLU.
The neural operator shares a similar framework. It’s just now and are functions with different discretizations (say, some inputs are , some are , and some are in triangular mesh). To deal with functions input, the linear transformation is formulated as an integral operator. Let be the points in the domain.
The map is parameterized as
Where is a kernel function and is the bias term.
For the Fourier neural operator, we formulate as a convolution and implement it by Fourier transformation.
Fourier Layer
The real-world images have lots of edges and shapes, so CNN can capture them well with local convolution kernel. On the other hand, the inputs and outputs of PDEs are continuous functions. It is more efficient to represent them in Fourier space and do global convolution.
There are two main motivations to use Fourier transformation. First, it’s fast. A full standard integration of points has complexity , while convolution via Fourier transform is quasilinear. Second, it’s efficient. The inputs and outputs of PDEs are continuous functions. So it’s usually more efficient to represent them in Fourier space.
The convolution in the spatial domain is equivalent to the pointwise multiplication in the Fourier domain. To implement the (global) convolution operator, we first do a Fourier transform, then a linear transform, and an inverse Fourier transform, As shown in the top part of the figure:
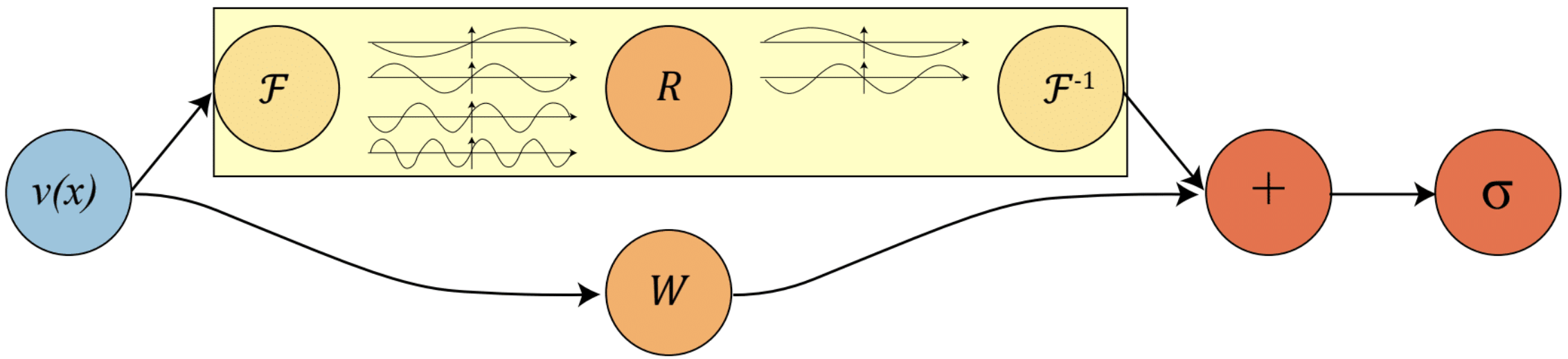
The Fourier layer just consists of three steps:
- Fourier transform
- Linear transform on the lower Fourier modes
- Inverse Fourier transform
We then add the output of the Fourier layer with the bias term (a linear transformation) and apply the activation function . Simple as it is.
In practice, it’s usually sufficient to only take the lower frequency modes and truncate out these higher frequency modes. Therefore, we apply the linear transformation on the lower frequency modes and set the higher modes to zeros.
Notice the activation functions shall be applied on the spatial domain. They help to recover the Higher frequency modes and non-periodic boundary which are left out in the Fourier layers. Therefore it’s necessary to the Fourier transform and its inverse at each layer.
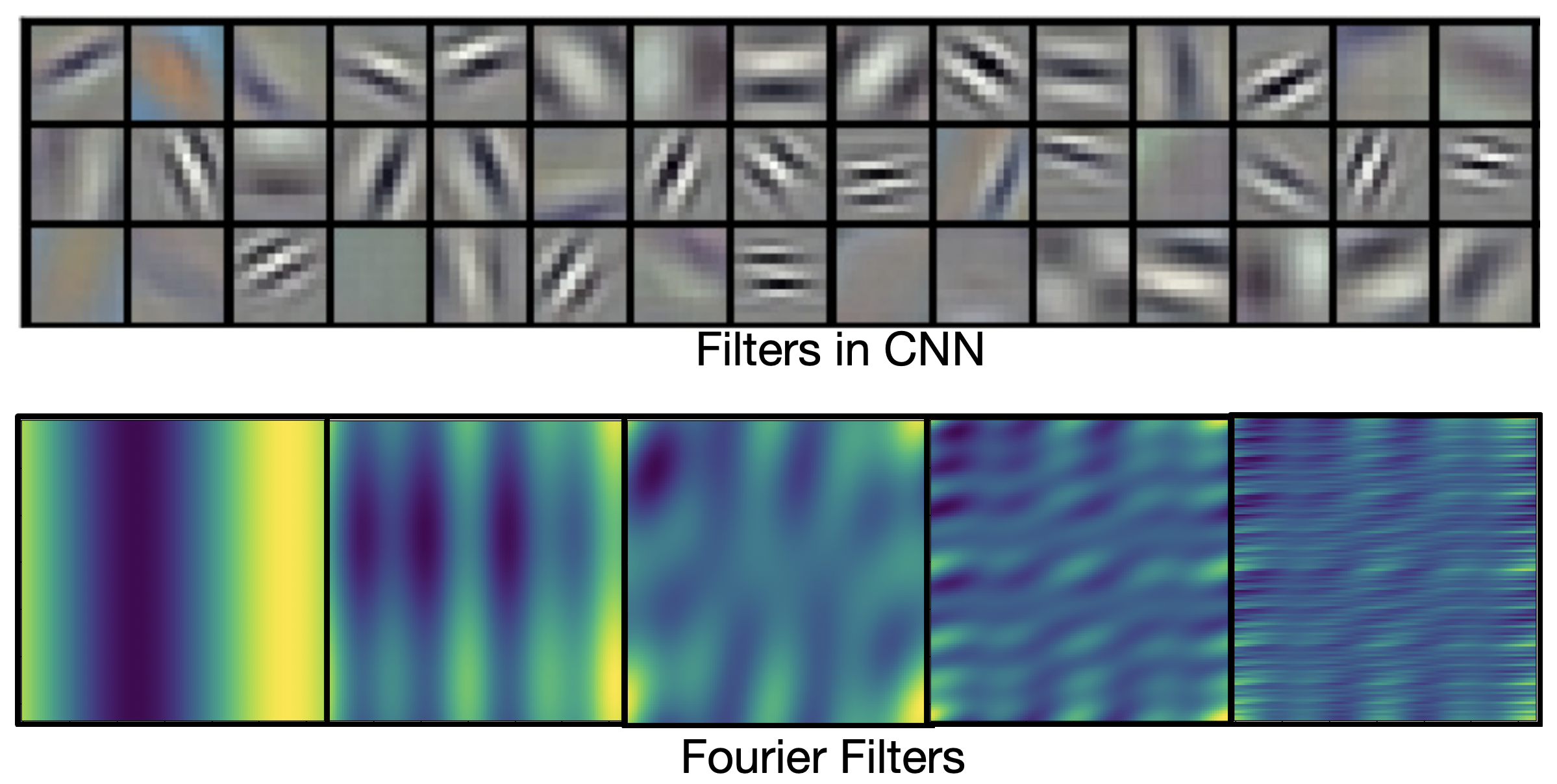
Filters in convolution neural networks are usually local. They are good to capture local patterns such as edges and shapes. Fourier filters are global sinusoidal functions. They are better for representing continuous functions.
Higher frequency modes and non-periodic boundary
The Fourier layer on its own loses higher frequency modes and works only with periodic boundary conditions. However, the Fourier neural operator as a whole does not have these limitations (examples shown in the experiments). The encoder-decoder structure helps to recover the higher Fourier modes. And the bias term helps to recover the non-periodic boundary.
Complexity
The Fourier layer has a quasilinear complexity. Denote the number of points (pixels) and truncating at frequency modes. The multiplication has complexity . The majority of the computational cost lies in computing the Fourier transform and its inverse. General Fourier transforms have complexity , however, since we truncate the series the complexity is in fact , while the FFT has complexity .
Resolution-invariance
The Fourier layers are discretization-invariant, because they can learn from and evaluate functions which are discretized in an arbitrary way. Since parameters are learned directly in Fourier space, resolving the functions in physical space simply amounts to projecting on the basis of wave functions which are well-defined everywhere on the space. This allows us to transfer among discretization. If implemented with standard FFT, then it will be restricted to uniform mesh, but still resolution-invariant.
Experiments
1. Burgers Equation
The 1-d Burgers’ equation is a non-linear PDE with various applications including modeling the one-dimensional flow of a viscous fluid. It takes the form
with periodic boundary conditions where is the initial condition and is the viscosity coefficient. We aim to learn the operator mapping the initial condition to the solution at time one, defined by for any .
| Networks | s=85 | s=141 | s=211 | s=421 |
|---|---|---|---|---|
| FCN | 0.0253 | 0.0493 | 0.0727 | 0.1097 |
| PCA+NN | 0.0299 | 0.0298 | 0.0298 | 0.0299 |
| RBM | 0.0244 | 0.0251 | 0.0255 | 0.0259 |
| LNO | 0.0520 | 0.0461 | 0.0445 | - |
| FNO | 0.0108 | 0.0109 | 0.0109 | 0.0098 |
2. Darcy Flow
We consider the steady-state of the 2-d Darcy Flow equation on the unit box which is the second order, linear, elliptic PDE
with a Dirichlet boundary where is the diffusion coefficient and is the forcing function. This PDE has numerous applications including modeling the pressure of the subsurface flow, the deformation of linearly elastic materials, and the electric potential in conductive materials. We are interested in learning the operator mapping the diffusion coefficient to the solution, defined by . Note that although the PDE is linear, the solution operator is not.
| Networks | s=256 | s=512 | s=1024 | s=2048 | s=4096 | s=8192 |
|---|---|---|---|---|---|---|
| FCN | 0.0958 | 0.1407 | 0.1877 | 0.2313 | 0.2855 | 0.3238 |
| PCA+NN | 0.0398 | 0.0395 | 0.0391 | 0.0383 | 0.0392 | 0.0393 |
| LNO | 0.0212 | 0.0221 | 0.0217 | 0.0219 | 0.0200 | 0.0189 |
| FNO | 0.0149 | 0.0158 | 0.0160 | 0.0146 | 0.0142 | 0.0139 |
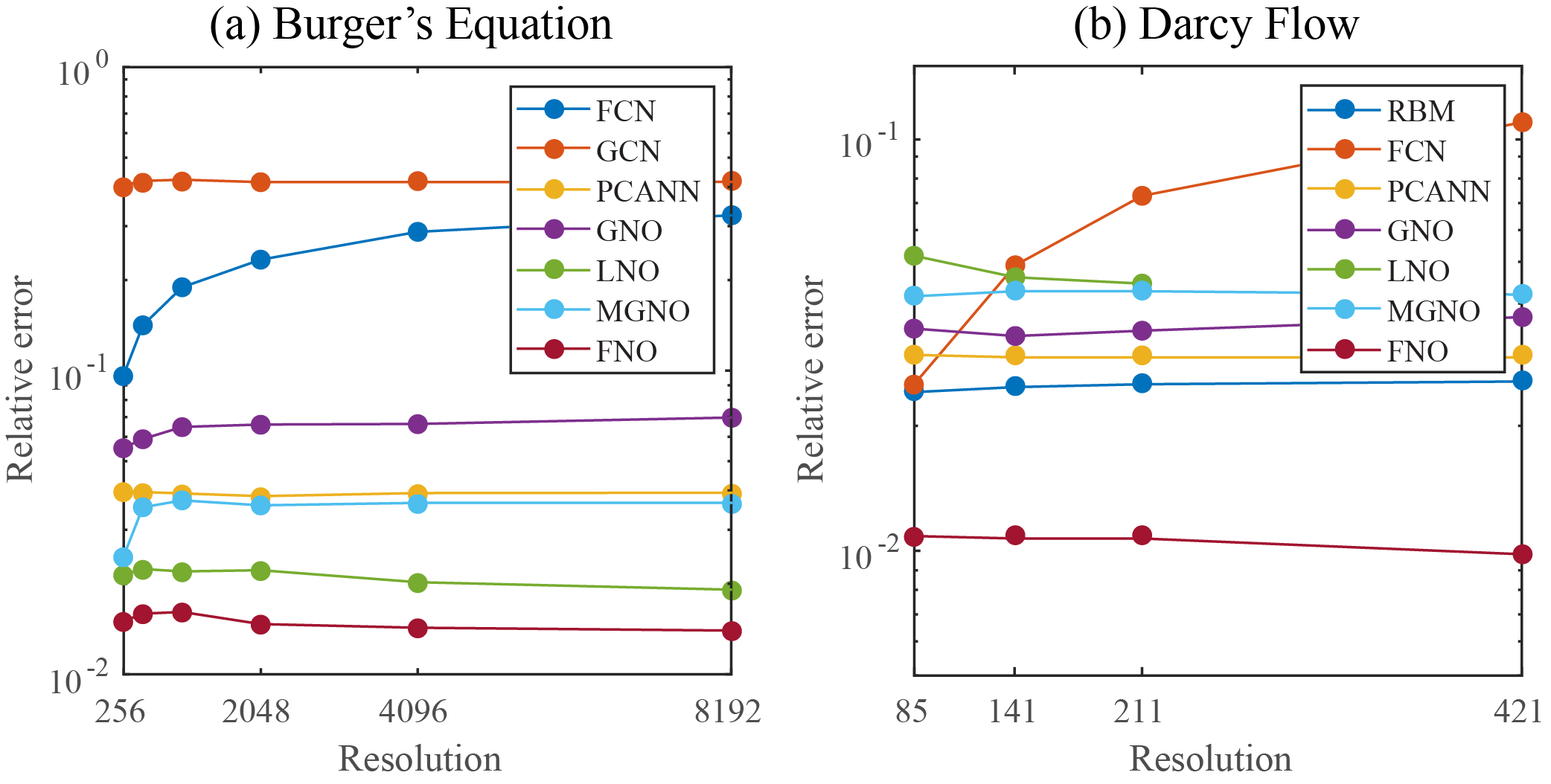
Benchmarks for time-independent problems (Burgers and Darcy):
- NN: a simple point-wise feedforward neural network.
- RBM: the classical Reduced Basis Method (using a POD basis).
- FCN: a the-state-of-the-art neural network architecture based on Fully Convolution Networks.
- PCANN: an operator method using PCA as an autoencoder on both the input and output data and interpolating the latent spaces with a neural network.
- GNO: the original graph neural operator.
- MGNO: the multipole graph neural operator.
- LNO: a neural operator method based on the low-rank decomposition of the kernel.
- FNO: the newly purposed Fourier neural operator.
3. Navier-Stokes Equation
We consider the 2-d Navier-Stokes equation for a viscous, incompressible fluid in vorticity form on the unit torus:
where is the velocity field,
is the vorticity,
is the initial vorticity,
is the viscosity coefficient,
and is the forcing function.
We are interested in learning the operator mapping the vorticity up to time 10
to the vorticity up to some later time ,
defined by .
We experiment with the viscosities
,
decreasing the final time as the dynamic becomes chaotic.
| Configs | Parameters | Time per epoch | |||
|---|---|---|---|---|---|
| FNO-3D | 6,558,537 | 38.99s | 0.0086 | 0.0820 | 0.1893 |
| FNO-2D | 414,517 | 127.80s | 0.0128 | 0.0973 | 0.1556 |
| U-Net | 24,950,491 | 48.67s | 0.0245 | 0.1190 | 0.1982 |
| TF-Net | 7,451,724 | 47.21s | 0.0225 | 0.1168 | 0.2268 |
| ResNet | 266,641 | 78.47s | 0.0701 | 0.2311 | 0.2753 |
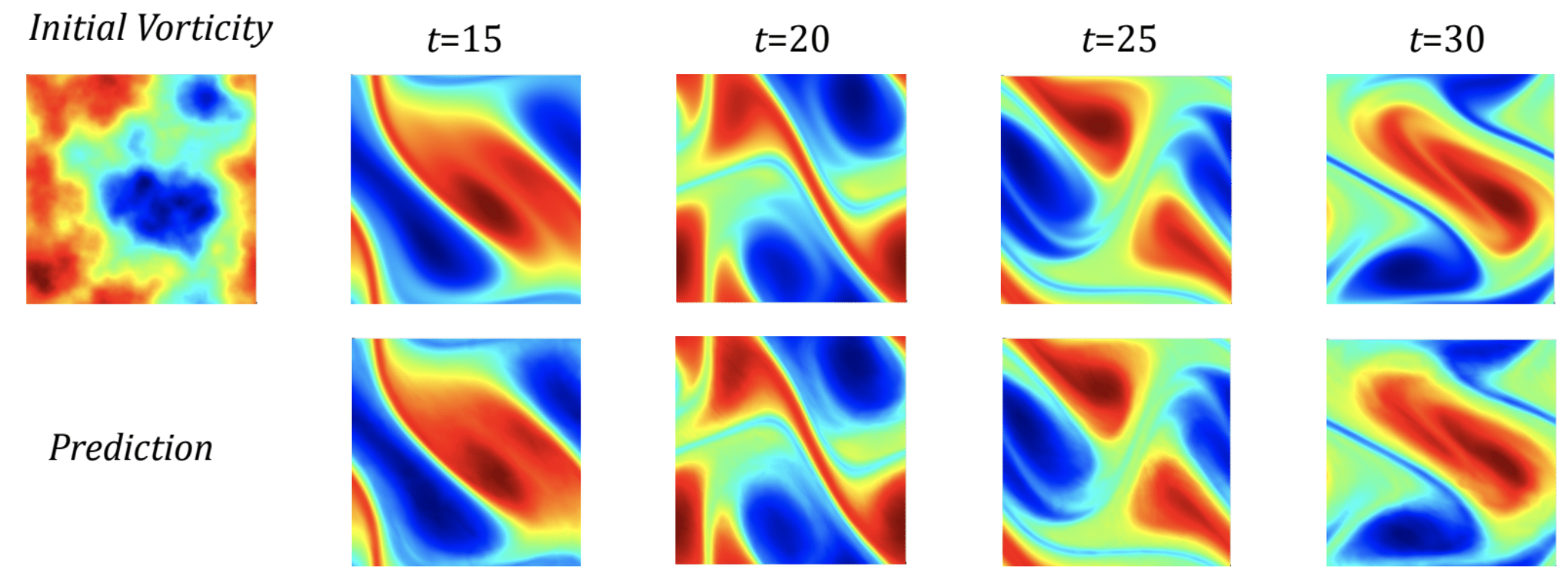
Benchmarks for time-dependent problems (Navier-Stokes):
- ResNet: 18 layers of 2-d convolution with residual connections.
- U-Net: A popular choice for image-to-image regression tasks consisting of four blocks with 2-d convolutions and deconvolutions.
- TF-Net: A network designed for learning turbulent flows based on a combination of spatial and temporal convolutions.
- FNO-2d: 2-d Fourier neural operator with an RNN structure in time.
- FNO-3d: 3-d Fourier neural operator that directly convolves in space-time.
The FNO-3D has the best performance when there is sufficient data ( and ). For the configurations where the amount of data is insufficient ( and ), all methods have error with FNO-2D achieving the lowest. Note that we only present results for spatial resolution since all benchmarks we compare against are designed for this resolution. Increasing it degrades their performance while FNO achieves the same errors.
FNO-2D, U-Net, TF-Net, and ResNet all use 2D-convolution in the spatial domain and recurrently propagate in the time domain (2D+RNN). On the other hand, FNO-3D performs convolution in space-time.
4. Bayesian Inverse Problem
In this experiment, we use a function space Markov chain Monte Carlo (MCMC) method to draw samples from the posterior distribution of the initial vorticity in Navier-Stokes given sparse, noisy observations at time . We compare the Fourier neural operator acting as a surrogate model with the traditional solvers used to generate our train-test data (both run on GPU). We generate 25,000 samples from the posterior (with a 5,000 sample burn-in period), requiring 30,000 evaluations of the forward operator.
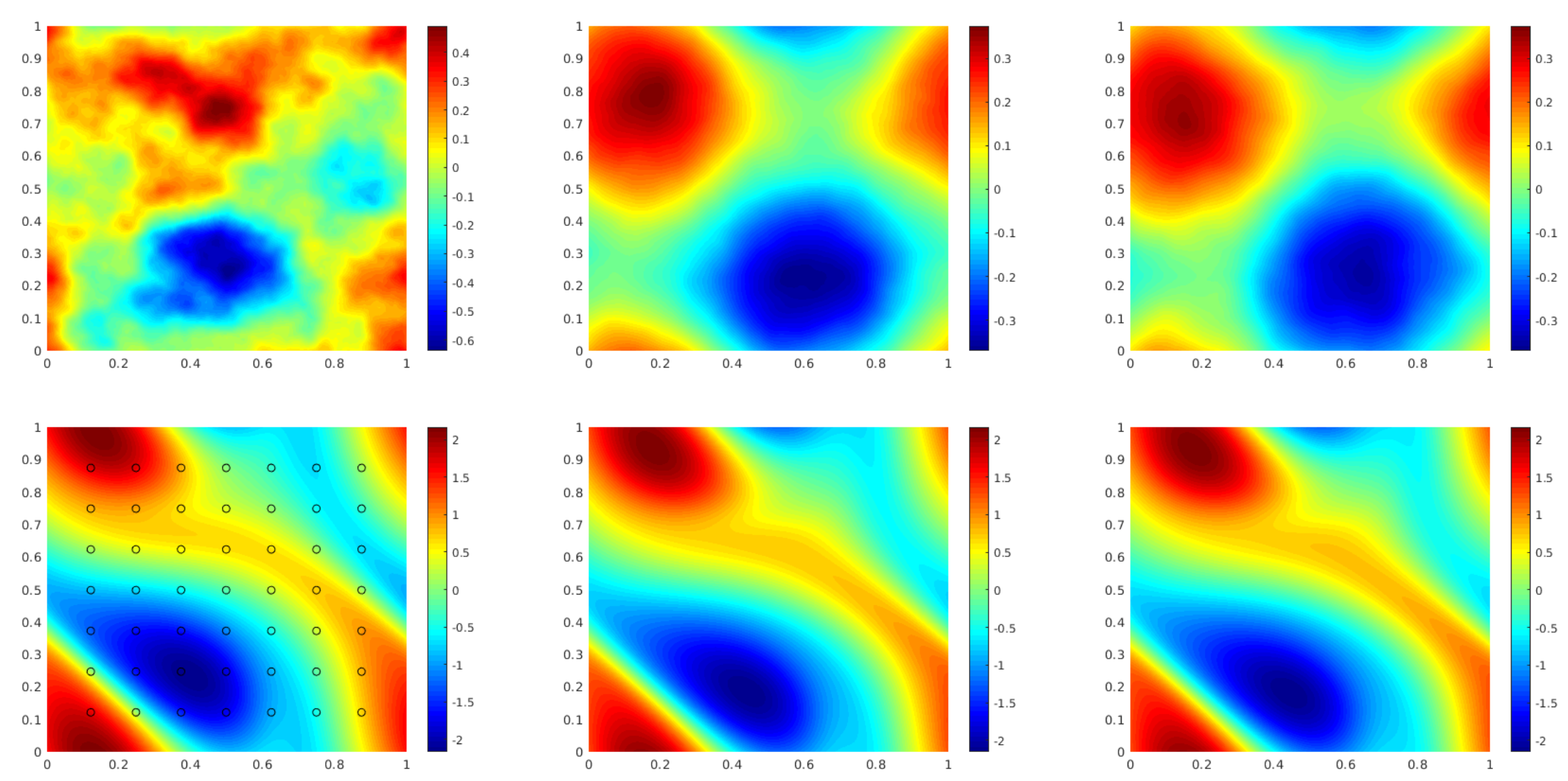
The top left panel shows the true initial vorticity while the bottom left panel shows the true observed vorticity at with black dots indicating the locations of the observation points placed on a grid. The top middle panel shows the posterior mean of the initial vorticity given the noisy observations estimated with MCMC using the traditional solver, while the top right panel shows the same thing but using FNO as a surrogate model. The bottom middle and right panels show the vorticity at when the respective approximate posterior means are used as initial conditions.
Conclusion
- We propose a neural operator based on Fourier Transformation. It is the first work that learns the resolution-invariant solution operator for the family of Navier-Stokes equation in the turbulent regime, where previous graph-based neural operators do not converge.
- By construction, the method shares the same learned network parameters irrespective of the dis- cretization used on the input and output spaces. It can do zero-shot super-resolution: trained on a lower resolution directly evaluated on a higher resolution.
- The proposed method consistently outperforms all existing deep learning methods for parametric PDEs. It achieves error rates that are lower on Burgers’ Equation, lower on Darcy Flow, and lower on Navier Stokes (turbulent regime with Reynolds number ).
- On a grid, the Fourier neural operator has an inference time of only compared to the of the pseudo-spectral method used to solve Navier-Stokes.